Ariën S. Rustenburg, Justin Dancer, Baiwei Lin, Jianweng A. Feng, Daniel F. Ortwine, David L. Mobley, and John D. Chodera.
Journal of Computer-Aided Molecular Design 30:945, 2016. [DOI] [bioRxiv] [PDF] // data: [GitHub]
Solicited manuscript for special issue of the Journal of Computer Aided Molecular Design on the SAMPL5 Challenge.
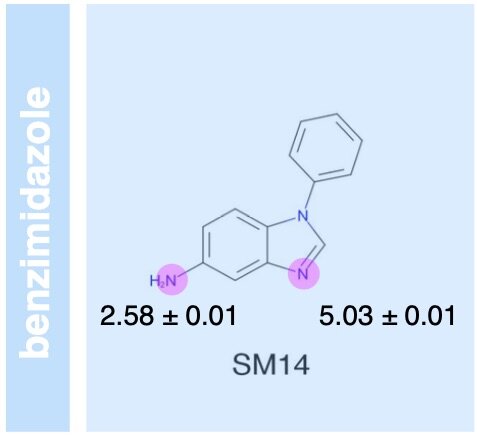
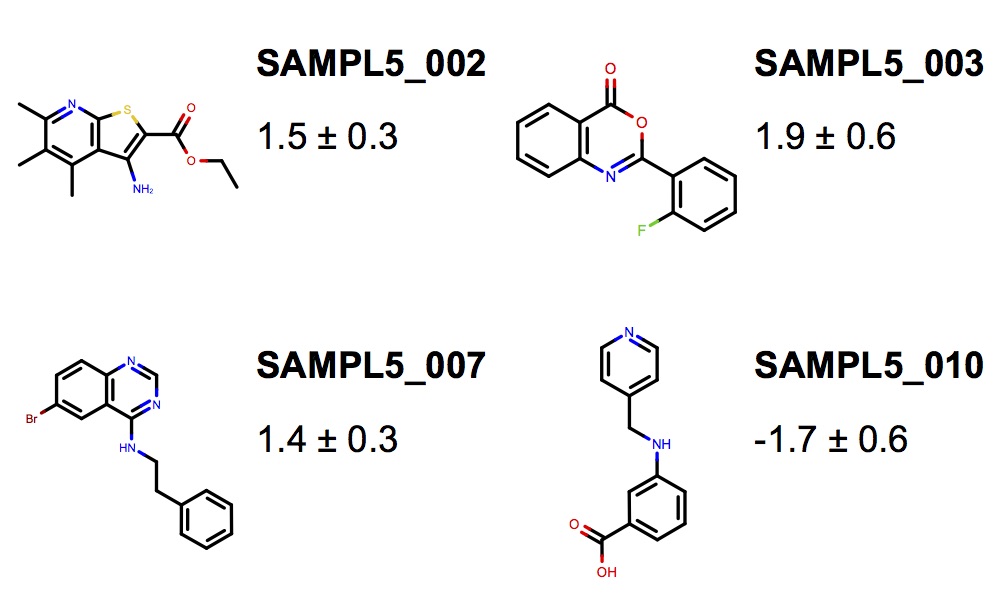
The SAMPL Challenges have driven predictive physical modeling for ligand:protein binding forward by focusing the community on a series of blind challenges that evaluate performance on blind datasets, focus attention on current challenges for physical modeling techniques, and provide high-quality experimental datasets to the community after the challenge is over. For many years, challenges focused around hydration free energies have proven to be extremely useful, with theory now able to determine when experiment is wrong. To replace these challenges, since no more hydration free energy data is being measured, we proposed to use the partition or distribution coefficients of small druglike molecules between aqueous and apolar phases. We report the collection of cyclohexane-water partition data for a set of compounds used to drive the SAMPL5 distribution coefficient challenge, providing the experimental data, methodology, and insight for future iterations of this challenge.